

- 빅데이터 적재 개요
- 빅데이터 적재에 활용되는 기술
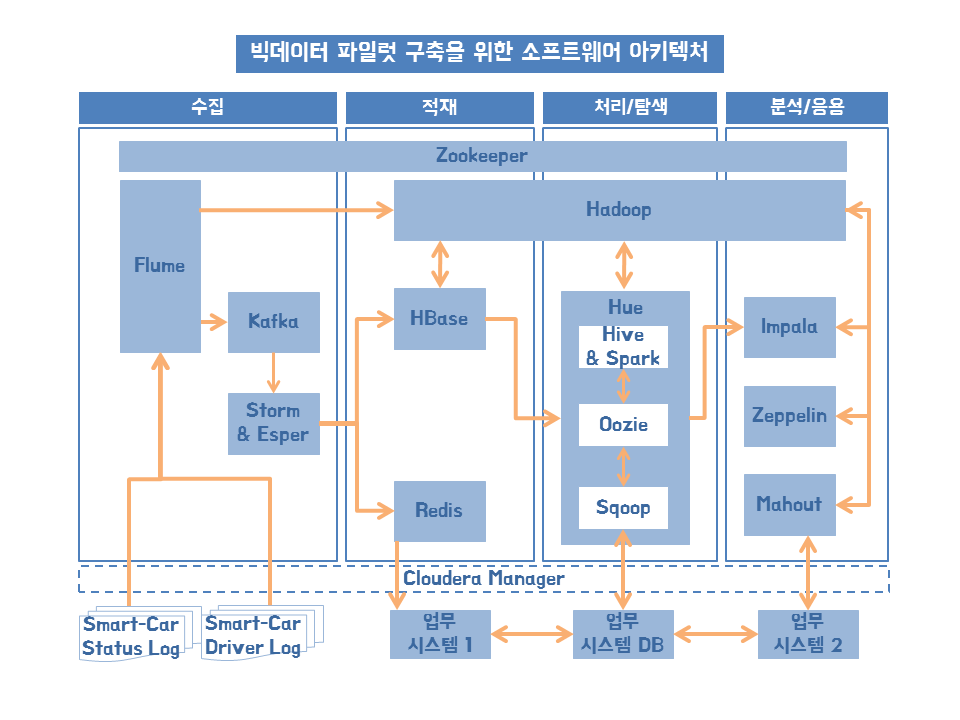
- 적재 파일럿 실행 1단계 - 적재 아키텍처
- 적재 파일럿 실행 2단계 - 적재 환경 구성
- 적재 파일럿 실행 3단계 - 적재 기능 구현
- 적재 파일럿 실행 4단계 - 적재 기능 테스트
빅데이터 적재 개요
- 수집한 데이터를 어디에, 어떻게 저장 할 것인가?
- 적재 후 분석 방식과 업무 시스템 성격에 따라 달리 구성
- 분산 파일, NoSQL, 메모리 캐시등
적재 저장소 유형 P138 그림 4-2 참고
내/외부 원천 데이터
- 정형 데이터 : 데이터베이스(관계/계층/객체/네트워크)
- 반정형 데이터: HTML / XML / JSON / 서버로그
- 비정형 데이터: 소셜미디어, 문서, 이미지, 오디오, 비디오, IoT
적재 저장소 유형
- 대용량 파일 전체 영구 저장 => 분산파일 시스템
- 대규모 메세지 전체 영구 저장 => NoSQL
- 대규모 메세지 전체 버퍼링 처리 => MOM(메세지지향 미들웨어)
- 대규모 데이터 일부 임시 저장 => Cached
- 메모리에 저장
빅데이터 적재
적재 - 대용량
- 배치성 처리
- 하루에 1번 하기로 '요구사항'에서 확인
적재 - 메세지
- 실시간성 처리
빅데이터 적재에 활용할 기술
하둡(Hadoop) - 맵리듀스(Map, Reduce) P142 그림 4.5 참고
- http://hadoop.apache.org
- 대용량 데이터 분산 저장 기능
- 분산 저장된 대용량 데이터 분석 기능
- Map : 일을 나누어 실행하는 작업
- Reduce : 나누어 실행한 결과 합
- DataNode : 블록(64MB or 128MB등) 단위로 분할 된 대용량 파일들이 DataNode 디스크에 저장 및 관리하는 서버
- NameNode: DataNode에 저장된 파일들의 메타 정보를 메모리상에서 로드해서 관리하는 서버
- EditsLog: 파일들의 변경 이력(수정, 삭제등) 정보가 저장되는 로그 파일
- FSImage : NameNode의 메모리상에 올라와 있는 메타 정보를 스냅샷 이미지로 만들어 생성한 파일
- *스냅샷 이미지 (그 시점까지 저장된 파일. ex)윈도우11 최종판 )
- Active/Stand-By NameNode: NameNode 이중화, Active NameNode 실패 대비
- 서버가 2개 있는 경우, 로드밸런싱ㅇ
- 경우에 따라서는 서버1로 1대 사용(Active)하고, 문제가 생기면 서버2를 사용(Stand-by)
- 저희는 'Active Active'에요. / 'Active Active Stnad-By' 에요
- MapReduce v2 / YARN: 하둡 클러스트 내의 자원을 중앙 관리하고 다양한 애플리케이션 실행 관리가 가능하도록 확장성과 호환성을 높인 하둡 2.X 플랫폼
- RosourceManager: 작업 요청시 스케줄링 정책에 따라 자원을 분배해서 실행시키고 모니터링
- NodeManager: DataNode 마다 실행되면서 Container를 실행 시키고 라이프사이클을 관리
- Container: DataNode의 사용 가능한 리소스(CPU, 메모리, 디스크등)를 Container 단위로 할당해 관리
- Container => 독립적, 개별적인 (단위)성격을 갖는다
- Tomcat 을 container라고 부른다. / 자바의 응답을 처리해주기 위해 독립적으로 존재하는 시스템.
- Docker / 컨테이너들을 가지고 독립적인 서버를 만드는 시스템
- ApplicationMaster: 애플리케이션이 실행되면 생성되며 NodeManager에게 Container를 요청하고 그 위에 애플리케이션을 실행 및 관리
- JournalNode: 3개 이상의 노드로 구성되어 EditsLog를 각 노드에 복제 관리하며 Active NameNode는 EditsLog에 쓰기 수행, Standby NameNode는 읽기 실행
위 내용들이 한 챕터, 한 챕터씩 이루어져있고 그에 해당하는 내용들이 있기 때문에 하둡이 책 한권.
하둡 구성
스마트카 상태 정보 CarLogMain 대용량
- 3초간격, 100M/day(대용량) : 플럼 => 하둡
- HDFS 특정 디렉토리에 일자 단위로 파티션에 적재
- 일/주/월/년 단위로 다양한 시계열 집계 분석 가능
- 하이브로 분석 => HDFS 특정 영역에 저장(Hive Data Warehouse) = > 스마트카 고급 분석
조건절에 쓰려고.
주키퍼(Zookeeper)
- http://zookeeper.apache.org
- 분산 코디네이터
- 서버 간의 정보를 쉽고 안전하게 공유
- 공유된 정보를 이용해 서버간 중요한 이벤트(분산락, 순서제어, 부하 분산, 네임서비스등)을 관리 및 상호 조율
- 하둡, HBase, 카프카, 스톰 등에서 분산 노드 관리에 사용
- Client : 주키퍼 Znode에 담긴 데이터에 대한 쓰기, 읽기, 삭제등의 작업 요청(직접 하는 경우는 많지 않다. 시스템끼리 일함)
- Znode: 주키퍼 서버에 생성되는 파일시스템의 디렉터리 개념으로 Client의 요청 정보를 계층적으로 관리
적재 파일럿 실행 1단계 - 적재 아키텍처
적재 요구사항
요구사항 1
- 차량의 다양한 장치로부터 발생하는 로그 파일을 수집해서 기능별 상태 점검
요구사항 구체화 및 분석
100대 스마트카 상태 정보 일단위로 취합 제공
- 플럼 수집 발생 시점의 날짜를 HdfsSink에 전달 해당 날짜 단위로 적재
상태 정보는 약 100MB/day , 220만건의 상태 정보
- 100대 - 하루에 220만 건의 상태 정보
- 1년 적재 시 8억건, 연단위 분석에 하둡 분산 병렬 처리 사용
데이터 발생일과 수집/적재되는 날 오차 발생 가능
- 발생일 외 수집/적재 처리되는 처리일 추가
일 / 월 / 년 단위로 분석 가능 해야 함
- HDFS에 수집 일자별로 디렉터리 경로 만들어 적재
적재 완료 후 원천 데이터는 삭제되야 함
- 플럼 Source 컴포넌트 중 SpoolDir 의 DeletePolicy 옵션 사용
- 즉시 지우도록 이미 설정해준 상태
적재 아키텍처
플럼 HDFS Sink
- 플럼 Source 에서 읽어 드린 데이터를 하둡에 적재시 다양한 옵션과 기능 사용
- 적재 시 사용 할 파일 타입, 이름, 크기 등 옵션은 주변 환경과 요구사항에 따라 최적화
HDFS의 파티션 적재
- 주로 날짜별 디렉토리 만들어 관리
- 업무코드 + 날짜 조합
- 하이브 사용시 파티션 디렉토리 조건으로 조회 전체 파일 스캔하지 않아 효율성이 높아짐
적재 파일럿 실행 2단계 - 적재 환경 구성
하둡 설치 및 관리
- 하둡 관리 화면 : http://server01.hadoop.com:9870
- CM > 하둡선택 > NameNode 웹 UI
- 리소스매니저 : http://server01.hadoop.com:8088/cluster
- 잡(job)히스토리: http://server01.hadoop.com:19888/jobhistory
- Yarn((MR2 Included) : JobHistory Server 자주 셧다운, 확인 필요
- 주의할 점. Yarn이 자꾸 종료되는 현상.
- Yarn > 인스턴스 > JobHistory Server > 재시작
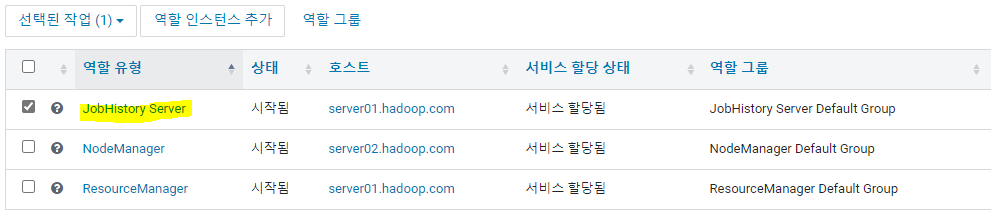
선택된 작업 > 시작
적재 파일럿 실행 3단계 - 적재 기능 구현
플럼에이전트 SmartCar 에이 전트 수정
- bigdata2nd-master\CH04\예제4.2\SmartCar_Agent.conf
- Logger Sink => HDFS Sink
HDFS Sink 정보를 설정하기 위한 리소스 선언
SmartCar_Agent.sinks = SmartCarInfo_LoggerSink DriverCarInfo_KafkaSink
=> SmartCar_Agent.sinks = SmartCarInfo_HdfsSink DriverCarInfo_KafkaSink3개의 인터셉터 추가
- 타임스탬프 활용을 위한 timeInterceptor
- 로그 유형 상수값 지정을 위한 typeInterceptor
- 수집일자 추가를 위한 collectDayInterceptor
- 자바파일을 연결시켜서, 그 자바파일이 읽는 역할
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors = timeInterceptor typeInterceptor collectDayInterceptor filterInterceptortimeInterceptor 인터셉터 설정
- 플럼 이벤트 헤더에 현재 타임스탬프 설정, 필요시 헤더에서 읽어 활용
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.timeInterceptor.type = timestamp
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.timeInterceptor.preserveExisting = truetypeInterceptor 인터셉터 설정
- logType 상수 선언 , 값은 car-batch-log
- static / 변수명 / 값
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.type = static
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.key = logType
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.typeInterceptor.value = car-batch-logcollectDayInterceptor 인터셉터 설정
- 자바파일로 생성.
type = 내가 만든 자바파일
- 이벤트 Body에 수집된 당일 작업 날짜 추가
- 기본 제공 아닌 추가 개발 사용자 정의 Interceptor => CollectDayInterceptor.java
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.interceptors.collectDayInterceptor.type = com.wikibook.bigdata.smartcar.flume.CollectDayIntercept
CollectDayInterceptor.java
- 플럼으로 수집되는 모든 데이터인 EventBody에 getToDate() 날짜 추가
implements Interceptor
@Override
public Event intercept(Event event) {
String eventBody = new String(event.getBody()) + "," + getToDate();
event.setBody(eventBody.getBytes());
return event;
}이벤트 바디를 자동으로 넣어준다. 날짜형으로 바꾸고. setBody (바이트형태로 자료형을 바꾸고 넣어준다)
package com.wikibook.bigdata.smartcar.flume;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
public class CollectDayInterceptor implements Interceptor {
public CollectDayInterceptor(){
}
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String eventBody = new String(event.getBody()) + "," + getToDate();
event.setBody(eventBody.getBytes());
return event;
}
@Override
public void close() {
}
@Override
public List<Event> intercept(List<Event> events)
{
for (Event event:events) {
intercept(event);
}
return events;
}
public static class Builder implements Interceptor.Builder
{
@Override
public void configure(Context context) {
}
@Override
public Interceptor build() {
return new CollectDayInterceptor();
}
}
public String getToDate() {
long todaytime;
SimpleDateFormat day;
String toDay;
todaytime = System.currentTimeMillis();
day = new SimpleDateFormat("yyyyMMdd");
toDay = day.format(new Date(todaytime));
return toDay;
}
}@Override
public Event intercept(Event event) { // (Event event) <- 넣어줄게
String eventBody = new String(event.getBody()) + "," + getToDate();
//String 으로 형변환
event.setBody(eventBody.getBytes());
return event;
}
HDFS Sink 상세 옵션 추가
- 외부 수행 명령 결과를 플럼 Event로 가져와 수집
- 동적으로 path 설정 => .hdfs.path = /pilot-pjt/collect/%{logType}/wrk_date=%Y%m%d
- 적재시 파일명 규칙, 파일 크기등 정의
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.path = /pilot-pjt/collect/%{logType}/wrk_date=%Y%m%d
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.filePrefix = %{logType}
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.fileSuffix = .log
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.fileType = DataStream
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.writeFormat = Text
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.batchSize = 10000
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollInterval = 0
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollCount = 0
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.idleTimeout = 100
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.callTimeout = 600000
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.rollSize = 67108864
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.threadsPoolSize = 10기존 소스 오류 남 - 아래 옵션 추가해야 함
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.hdfs.useLocalTimeStamp = true
Source와 Channel Sink 연결
SmartCar_Agent.sources.SmartCarInfo_SpoolSource.channels = SmartCarInfo_Channel
SmartCar_Agent.sinks.SmartCarInfo_HdfsSink.channel = SmartCarInfo_Channel
적재 파일럿 실행 4단계 - 적제 기능 테스트
플럼 구성 수정 및 인터셉터 라이브러리 추가
- 플럼 구성 파일 수정
- CollectDayInterceptor.java 추가 => bigdata.smartcar.flume-1.0.jar(CH04폴더)
- 플럼라이브러리 경로: Server02 : /opt/cloudera/parcels/CDH/lib/flume-ng/lib
- 플럼 재시작
SmartCar 로그 시뮬레이터 작동 100대
- Sever02 SSH 접속 시뮬레이터 위치로 이동
- 파일 생성 위치 확인
- 파일 생성 확인 : SmartCarStatusInfo_20220906.txt
# cd /home/pilot-pjt/working
# ls -l /home/pilot-pjt/working/SmartCar/
# java -cp bigdata.smartcar.loggen-1.0.jar com.wikibook.bigdata.smartcar.loggen.CarLogMain 20220906 100
# ls -l /home/pilot-pjt/working/SmartCar/
# tail -f /home/pilot-pjt/working/SmartCar/SmartCarStatusInfo_20220906.txt
-a : add 모드
-G : 그룹 파일
플럼 이벤트 사용자 생성
# cat /etc/group | grep supergroup
# groupadd supergroup
# usermod -a -G supergroup flume
# usermod -a -G supergroup hdfs
# cat /etc/group | grep supergroup플럼 이벤트 작동
- SmartCarStatusInfo_20210901.txt 을 SpoolDir 경로로 이동
# cd /home/pilot-pjt/working/SmartCar/
# tail -f /var/log/flume-ng/flume-cmf-flume-AGENT-server02.hadoop.com.log
# mv SmartCarStatusInfo_20210101.txt ../car-batch-log/
Creating /pilot-pjt/collect/...
Writer callback called (적재 완료)HDFS 명령어 확인
- 모든 목록 확인 : 64M 씩 나눠져서 wrk_data=날짜 로 생성
# hdfs dfs -ls -R /pilot-pjt/collect/car-batch-log/- 내용 확인
# hdfs dfs -cat /pilot-pjt/collect/car-batch-log/wrk_date=20200901/car-batch-log.1573369259554.log
# hdfs dfs -tail /pilot-pjt/collect/car-batch-log/wrk_date=20200901/car-batch-log.1573369259554.log
- 삭제 : 바로 폴더 이하 삭제
hdfs dfs -rm -r -skipTrash /pilot-pjt/collect'Hadoop > 빅데이터 파일럿 프로젝트' 카테고리의 다른 글
| 빅데이터 적재 - 실시간 로그 파일 적재 / 환경 구성(2) (0) | 2022.09.07 |
|---|---|
| 빅데이터 적재 - 실시간 로그 파일 적재(1) (0) | 2022.09.06 |
| [Hadoop] 빅데이터수집 (0) | 2022.09.06 |
| [Hadoop] 빅데이터 파일럿 프로젝트_ 파일럿 환경 구성 (0) | 2022.09.05 |
| [Hadoop] 빅데이터 파일럿 프로젝트_ 스마트카 로그 시뮬레이터 설치 (0) | 2022.09.05 |



