
- 빅데이터 탐색 개요
- 빅데이터 탐색에 활용되는 기술
- 탐색 파일럿 실행 1단계 - 탐색 아키텍처
- 탐색 파일럿 실행 2단계 - 탐색 환경 구성
- 탐색 파일럿 실행 3단계 - 탐색 기능 구현
- HDFS에 적재된 데이터 확인 : 파일 브라우저
- HBase에 적재된 데이터 확인
- 하이브를 이용한 External 데이터 탐색(1)
- 하이브를 이용한 External 데이터 탐색(2)
- 데이터셋 추가
- Hive SmartCar_Master 테이블 생성
- Hive SmartCar_Item_BuyList 테이블 생성
- Spark를 이용한 추가 데이터 탐색
- 탐색 파일럿 실행 4단계 - 탐색 기능 테스트
탐색 파일럿 실행 3단계 - 휴를 이용한 데이터 탐색
- CM > Hue > 웹 UI > admin / admin
- http://server02.hadoop.com:8888/
HDFS에 적재된 데이터 확인 : 파일 브라우저
- 햄버거메뉴 > 브라우저 > 파일
- /user/admin => /pilot-pjt/collect/car-batch-log/wrk_data=20160101
- 파일 내용 확인도 가능
HBase에 적재된 데이터 확인
- 햄버거메뉴 > 브라우저 > HBase
- DriverCarInfo Table , 내용 확인
- 저사양은 확인 후 서비스 중지
하이브(Hive)를 이용한 External 데이터 탐색
- 상단메뉴 > 쿼리 > 편집기 > HiveSmartCar_Status_Info 테이블 생성
- External 데이터: /pilot-pjt/collect/car-batch-log/wrk_data=20210101
- Query Editors => Hive => \bigdata-master\CH06\HiveQL\2nd
- 그림-6.44.hql (Drag and Drop) => Hive External 테이블 생성
- 스키마가 없는 데이터 파일을 하이브 스키마로 정의 메타스토어에 등록
- QL로 해당 파일 접근 가능
- 그림-6.45.hql (Drag and Drop) => 작업일자 기준 파티션 정보 생성(wrk_data=20210101 날짜로 생성)
- 쿼리실행 : 그림-6.46.hql (Drag and Drop) => limit 절사용 빠른 조회
- 쿼리오류 시 파일럿 프로젝트는 default 사용 확인
- 쿼리기록 : 기존 사용했던 쿼리 확인 가능
- 쿼리 연습 : 그림-6.48.hql
select car_number, avg(battery) as battery_avg
from SmartCar_Status_Info
where battery < 60
group by car_number;- Job Browser메뉴를 통해 변환 실행된 맵리듀스 정보로 확인 가능
데이터셋 추가
- 파일 브라우저에서 작업
- 스마트카 마스터 데이터 : Ch06/CarMaster.txt
- 스마트카 차량용품 구매 이력 데이터: Ch06/CarItemBuyList_201606.txt
- 휴 파일 브라우저 업로드 기능 이용 => 하이브 External Table 로 정의
CarMaster.txt
- /pilot-pjt/collect/car-master 생성 후 CarMaster.txt 업로드
- 차량번호|성별|나이|결혼여부|지역|직업|차량용량|차량연식|차량모델
CarItemBuyList_201606.txt
- /pilot-pjt/collect/buy-list 생성 후 CarItemBuyList_201606.txt 업로드
- 차량번호|구매상품코드|만족도(1-5)|구매월
Hive SmartCar_Master 테이블 생성
- QE > Hive > 그림-6.58.hql
select * from smartcar_master;Hive SmartCar_Item_BuyList 테이블 생성
- QE > Hive > 그림-6.60.hql
select * from smartcar_item_buylist limit 10;Spark를 이용한 추가 데이터 탐색
- 스마트카 마스터 데이터를 Spark-SQL 사용 탐색
- Age 18세이하는 실소유주가 아닐수 있어 이를 정제 작업 진행
- Spark Shell 사용
- Server02 ssh 접속
- spark-shell
- scala> var smartcar_master_df = spark.sqlContext.sql("select * from smartcar_master where age >= 18")

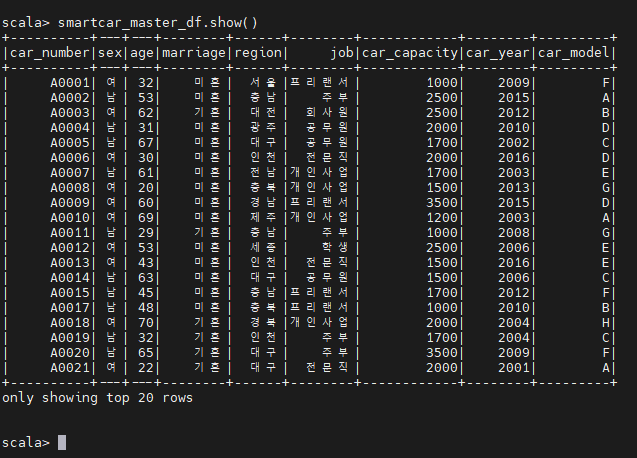
- scala > smartcar_master_df.show()
- scala > smartcar_master_df.write.saveAsTable("SmartCar_Master_Over18")
- QE > smartcar_master_over18 생성 확인
select * from smartcar_master_over18 where age > 30 and sex = '남'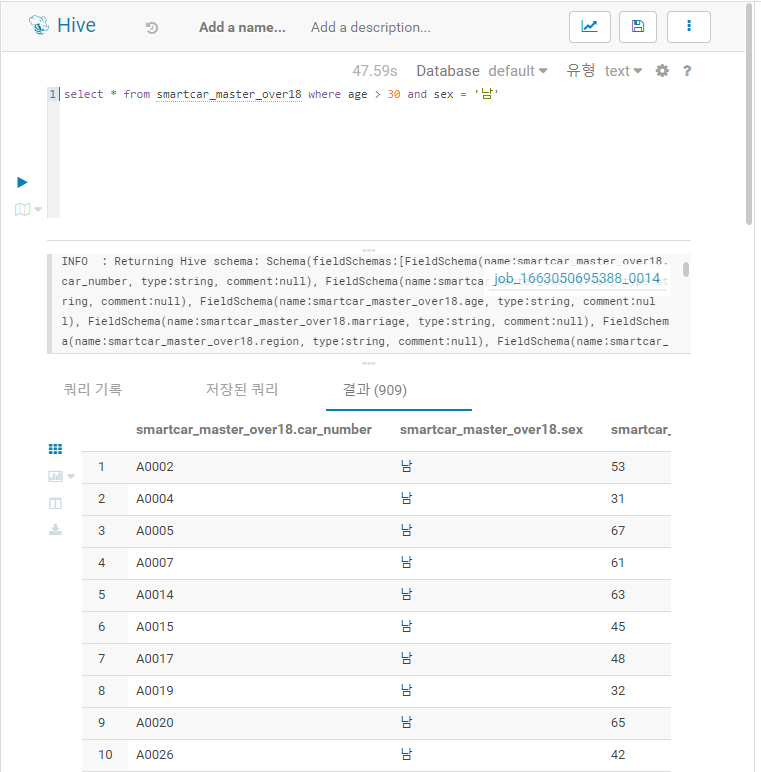
참고:
- spark 가 hive 보다 3배 정도 빠름
- 7장에서 제플린프로그램에서 Spark를 웹UI로 사용 가능
'Hadoop > 빅데이터 파일럿 프로젝트' 카테고리의 다른 글
| 빅데이터 분석 - 개요 및 기술 (0) | 2022.09.14 |
|---|---|
| 탐색 파일럿 실행 4단계 - 탐색 기능 테스트 (0) | 2022.09.07 |
| 탐색 파일럿 실행 2단계 - 탐색 환경 구성 (0) | 2022.09.07 |
| 탐색 파일럿 실행 1단계 - 아키텍처 (0) | 2022.09.07 |
| 빅데이터 적재 - 실시간 로그 파일 적재 / 환경 구성(2) (0) | 2022.09.07 |



